
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- ios
- iOS앱배포
- Xib
- JavaScript
- 파이썬서버
- 스위프트
- FLASK
- customclass
- Python
- 앱버전구하기
- iOS배포
- AJAX
- iOS계산기
- 맥
- spring
- 자바스크립트
- 딩동말씀
- 계산기앱
- FileOwner
- 계산기앱만들기
- 웹
- Xcode
- jQuery
- subscript
- Swift
- 앱배포
- MainScheduler
- DispatchGroup
- 개발기록
- 스프링
- Today
- Total
개발하는 뚝딱이
컴퓨터 네트워크 ch2(5) 본문
P2P Application
Properties
- No central control, no central database
- No hierarchy
- Every node is both a client and a server
- The communication between peer is symmetric
- No global view of the system
- Scalability
- Availability for any peer
- Peers are autonomous
- System globally unreliable
- Robustness and security issues
Napster : centralized directory
original "Napster" design
1) peer가 연결되면, directory server에게 IP address와 content를 알려준다.
2) Alice는 directory server에게 "Hey Jude"의 query를 던진다.
3) Directory server는 Bob이 "Hey Jude"를 갖고 있다고 알린다.
3) Alices는 Bob에게 file을 요청한다
4) Bob은 Alice에게 file을 준다

- File-sharing system
- Almost distributed system
- The location of a document is centralized
- The "transfer" is peer-to-peer
- Fast querying
- Problems
- Robustness : single point of failure - centralized server가 fail되면 서비스는 끝난다! (centralized service의 단점)
- Scalability : Performance bottleneck
- Copyright infringement : Sentenced to go out of business
Gnutella : Query flooding
- fully distributed P2P protocol
- no central server
- public domain protocol
- many Gnutella clients implementing protocol
- Gnutella protocol
- Based on broadcast/back-propagation mechanism over an overlay network
- Message types
- Ping/Pong : for group membership
- Query/Query Hit : for search
Overlay Networks

IP망이 있는데, 이 중에 service에 involved된 node들 간에 논리적인 망을 만드는 것.
물리적으로는 멀리 떨어져 있지만, 논리적으로는 neighbor가 되어 메시지를 주고받아 원하는 서비스를 함.
Gnutella : Join operation

GnuCache : user가 Gnu를 시작하려고 할 때, 처음에 기본적인 조그만 정보가 필요하다. 그것을 GnuCache라고 부른다.
1. 서비스를 하고 있는 list를 GnuCache에 물어본다.
2. 가장 seed가 된 node의 정보를 가르쳐줌
3. A가 B에게 join request를 보낸다.
4. B는 별 문제가 없으면 accept하고 grant request를 보낸다
Gnutella는 4개 정도 neighbor에 대한 정보를 유지한다.
5. C도 4개 neighbor에 대한 정보를 유지하는데, 주기적으로 ping message를 보낸다.
5'. 받으면 pong으로 응답한다.
5''. UserX는 C가 서비스를 하고 있다는 정보를 자신의 neighbor에게 보낸다
5'''. neighbor B는 또 UserA에게 정보를 보낸다.
6. 처음에 UserA는 neighborB 밖에 몰랐는데, neighbor 수가 충분하지 않으면 정보를 받아서 C에게 join request를 보내어 neighbor관계를 형성한다.
Gnutella : Search

1. neighbor에게 TCP connection을 통해 찾고자 하는 것을 query를 날린다.
2. 정보가 있으면 QueryHit을 날리고, 없으면 자신의 neighbor에게 Query를 날린다.
3. QueryHit을 받은 맨 처음 user는 직접 http 프로토콜을 이용하여 자료를 요청한다.
문제 :: broadcast strom - 1를 받아서 N개를 날리고... traffic이 엄청나다.
해결 :: Limited scope flooding - 돌고 돌아서 자신에게 query가 돌아올 수 있다. hop수가 많아지면 제한시켜 동작을 시킨다.
Gnutella
- Gnutella is simple, however Slow information discovery
- Excessive query traffic
- can be controlled through TTL (limited-scope query flooding) ; TTL value을 한 hop 당 -1하여 0이 될 때까지로 제한시킨다
- Query radius
- Limited flooding reduces the number of peers
- Maintenance of overlay network
- TCP connection between peer neighbors should be maintained even when there is no traffic
- centralized directory server 없이 빠르게 정보를 찾는가!!!
- Free riding!!!
- Most Gnutella users do not provide files to share
- 47% of all responses are returned by top 1% of hosts
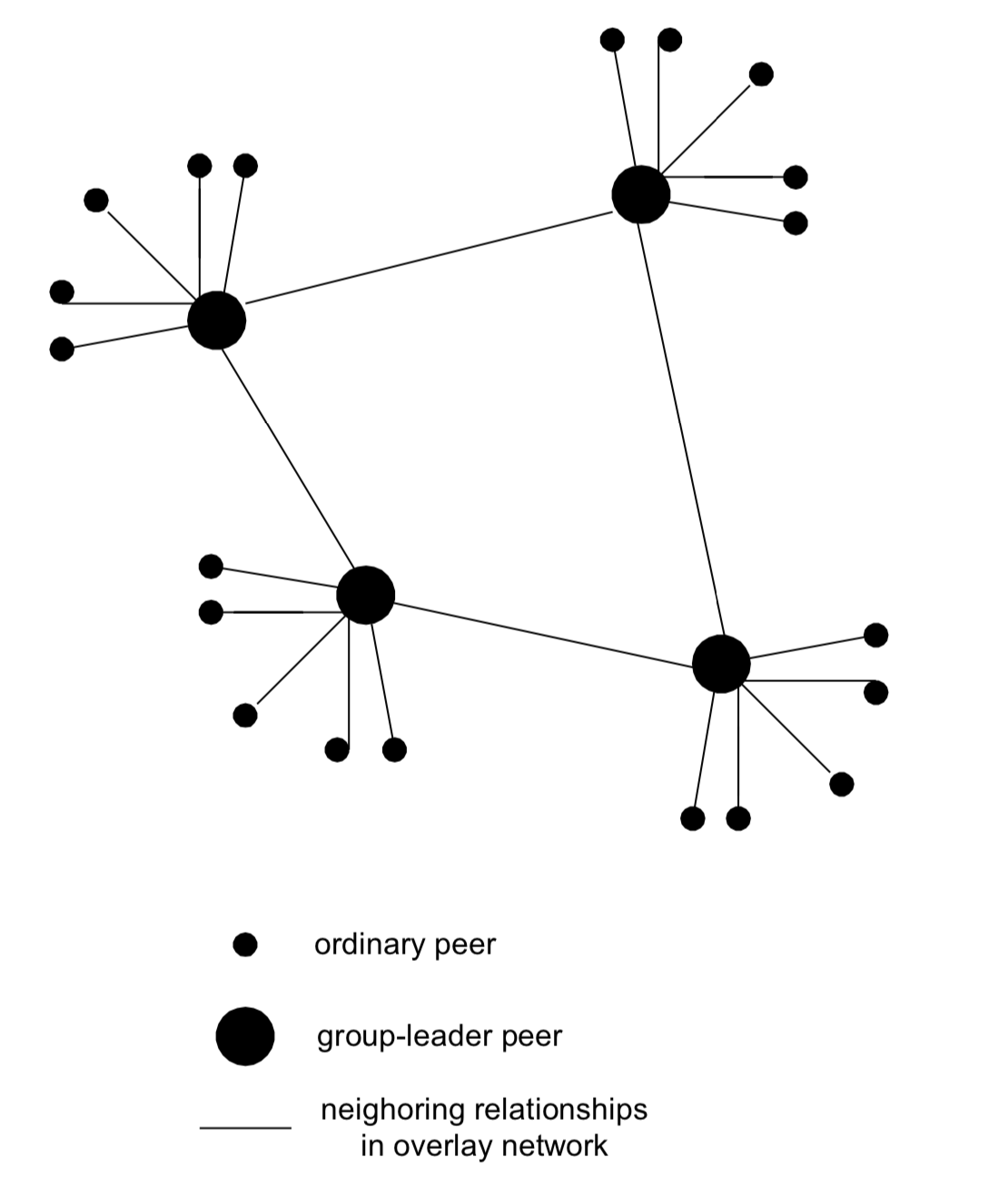
Hierarchical Overlay
- between centralized index, query flooding approaches
- each peer is either a group leader (super-peer) or assigned to a group leader
- TCP connection between peer and its group leader
- TCP connections between some paris of group leaders
- super-peer에게 물어보고, super-peer의 children에게 정보가 없으면 다른 super-peer에게 물어본다.
- 다른 super-peer에게서 정보를 받아 다시 알려주면, 직접 정보를 주고 받는다.
- group leader tracks content in its children
Client-server와 P2P 의 비교
한 서버에서 N개의 다른 컴퓨터로 처음에 파일을 분산시킬 때 얼마나 시간이 걸리는가?

1. 서버가 전달해야 하는 traffic의 양 = $ NF $
2. upload rate = $ NF / u_s$
[ N이 커지면, upload rate도 같이 커진다.]
3. $client_i$ 에게 전달되는 시간 = $ F/d_i $
[N과 무관]
N이 커지면 client-server distribution time이 linear하게 증가한다.

1. 서버가 정보를 보내는 시간 = $F/u_s$
2. client가 F라는 정보를 받는 시간 = $F/d_i$
각각의 peer에서 download할 때 가장 오래 걸리는 시간 = $F/min(d_i)$
3. NF라는 정보를 가장 최대치로 서비스할 때의 시간 = $ NF/(u_s + \sum_{i=1}^{N}{u_i}) $
3. max {$F/u_s$, $F/min(d_i)$, $ NF/(u_s + \sum_{i=1}^{N}{u_i}) $}
N이 증가하면 $ NF/(u_s + \sum_{i=1}^{N}{u_i}) $에서 분자, 분모 모두 증가

P2P - Bit Torrent
P2P file distribution
tracker : tracks peers participating in torrent
torrent : group of peers exchanging chunks of a file

- file divided into 256KB chunks
- peer joining torrent:
- has no chunks, but will accumulate them over time
- registers with tacker to get lists of peers, connects to subset of peers("neighbors")
- 다운로드하며, 자신의 chunk를 다른 peer에게 업로드한다
- peers may come and go
- once peer has entire file, it may (selfishly) leave or (altrustically) remain)
Requesting Chunks
- at any given time, different peers have different subsets of file chunks
- periodically, Alice asks each neighbor for list of chunks that they have
- Alice issues requests for her missing chunks
- 가장 귀한 정보를 먼저 요청 (rarest first)
Sending Chunks
- Alice sends chunks to four neighbors currently sending her chunks at the highest rate
- re-evaluate top 4 every 10 secs
- free riding을 막기 위한 것! ; 아무 정보도 안갖고 있는 사람은? 그래서 every 30secs.
- every 30 secs : randomly select another peer, starts sending chunks
- newly chosen peer may join top 4
Bit Torrent : Tit-for-tat
- Alice가 Bob에게 chunks를 우선 보낸다.
- Alice는 Bob의 top-four provider가 되고, Bob도 똑같이 chunks를 보낸다.
- Bob도 Alice의 top-four provider가 된다.

Distributed Hash Table (DHT)
hashtable은 분산되어 있다.
centralized directory server 없이 정보를 잘 분산시키기 위해서, Gnutella에서는 정보를 찾는데 오래 걸려서, 빨리 찾기 위해 나온 개념

DHT = a distributed P2P database
- Distributes data among a set of nodes according to predefined rules
Database has (object ID, value) pairs;
- Object ID : ss number, Value : human name
- Object ID : movie title, Value : IP address
Peers query values that match the key
In DHT-based networks each peer has a partial knowledge about the whole network. This knowledge can be used to route the queries to the responsible nodes using effective and scalable procedures.
How to assign keys to peers?
central issue :
- assigning (key, value) pairs to peers
basic idea :
- convert each key to an integer
- Assign integer to each peer
- put (key, value) pair in the peer that is closest to the key
Peer IDs and object IDs are in the same range
- Assign an integer to each peer or each object in rage [0, $2^n-1$]
- key = hash (object name)

Consistent hashing
새로운 node가 조인하여, DHT의 DB에 저장되거나 갑자기 node가 빠져나가면?
이 정보를 다른 node에게 알려줘야 하는데, 모두 reset하고 재배정할 수 없다!
이를 해결하기 위해 consistent hashing으로, 하나의 node가 추가되거나 제거되더라도 다른 key의 mapping에 영향을 주지 않아야 한다.



갑자기 Peer ID 3이 빠져나가면?
- H(commnet_lec1.pdf)는 7번에 저장된다. ID succ(2) = 7
- 나머지 애들은 영향받지 않는다!
네트워크를 구성하는데, get()과 put()으로만 간단히 구성되어 있다!
Put(hash(key), value), get(key)
Query를 보냈을 때, 찾는데 얼마나 걸리는가?
O(N) : N = the number of nodes [정보가 없으면, ring을 따라 확인하므로]
O(logN)이 될 수도 있다! [중간쯤에 정보를 갖고 있으면...]
Consider how to handle peer chun
어떤 node가 서비스에 가입하거나 빠져나가는 것을 chun. chun rate는 평균적으로 초당 몇 번 변동이 있는가
'컴퓨터 네트워크' 카테고리의 다른 글
| 컴퓨터 네트워크 ch1(4) (1) | 2019.10.15 |
|---|---|
| 컴퓨터 네트워크 ch2(6) (0) | 2019.10.10 |
| 컴퓨터 네트워크 ch2(4) (0) | 2019.10.09 |
| 컴퓨터 네트워크 ch2(3) (0) | 2019.10.08 |
| 컴퓨터 네트워크 ch2 (2) (0) | 2019.10.08 |



